Project description
Overview
During the last decade, artificial intelligence (AI) has received particular attention from academic and industrial communities. This made it possible to develop complex systems, such as those required for Autonomous Driving (AD) and Advanced Driver-Assistance Systems (ADAS). These systems process a large amount of data, on which a series of AI inferences are applied. Typical research interests in the AI community focus on improving recognition rates, without considering AI inference execution constraints. In this project, we want to improve both predictability and efficiency of running AI deep learning (DL) inferences, by exploiting their characteristics to enable their timing-aware implementations with novel scheduling policies, onto complex high-performance heterogeneous embedded computing platforms. The HeRITAGES project will achieve these goals by (i) evaluating timing performances of running DL implementations on different compute elements, to characterize and extract their execution features, (ii) modeling complex DL Inference workloads, composed of dependent DL inferences with the HPC-DAG task model; (iii) studying the impact of the extracted features such as task memory footprint and inter-task interference on resources co-scheduling and (iv) finally, designing novel scheduling frameworks to support the proposed approaches in HeRITAGES project.
HeRITAGES approach
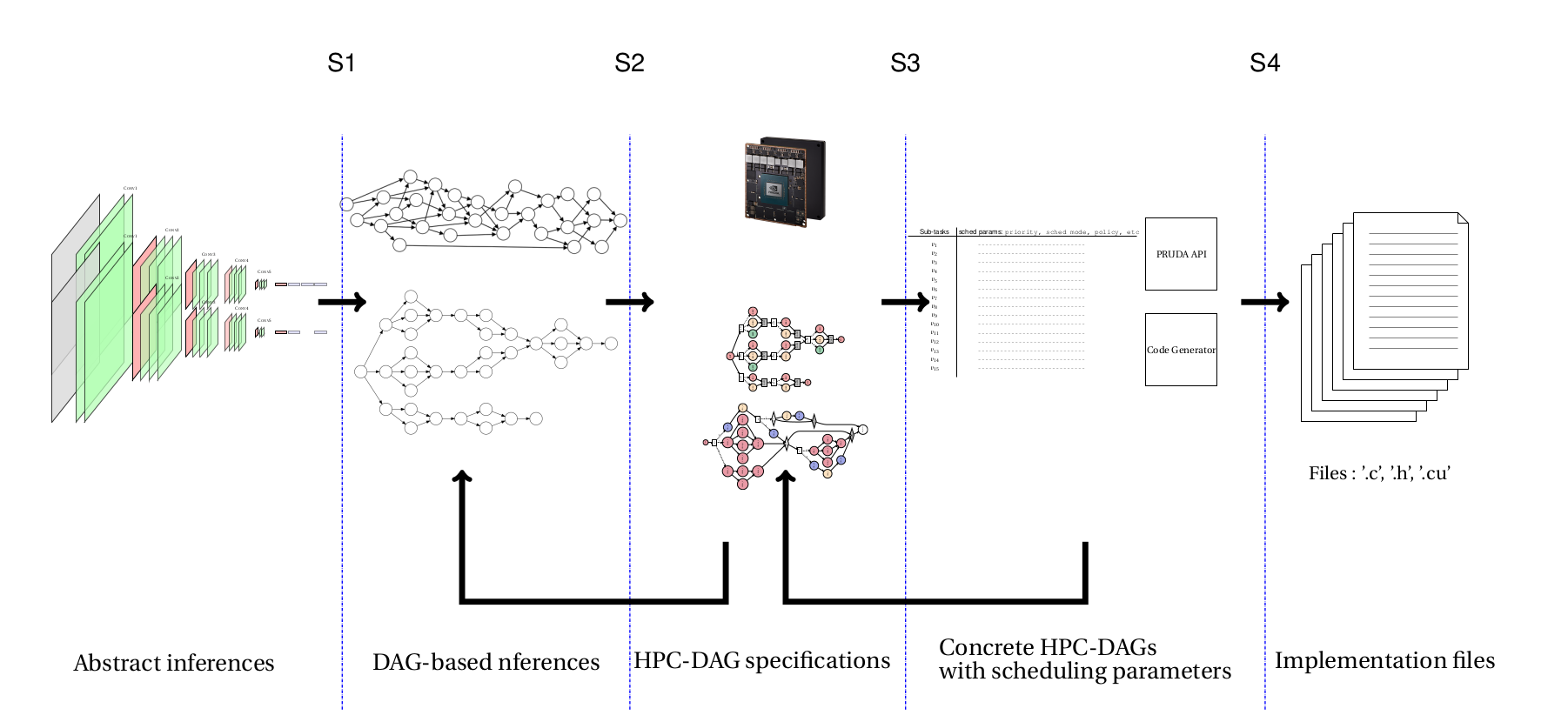
The HeRITAGES project has an integral approach, i.e., it targets to provide the design of a complete prototype framework that takes as input DL Inferences architecture, their dependencies, a hardware platform model and is able after multiple graph transformations to generate code for a timeliness valid real-time implementation of the system in input. The HeRITAGES approach workflow is organized through 4 stages, as shown in Figure ??.
- S1: The first stage, denoted as S1 in the figure, will allow having the first transformation of the DL inference design to a DAG. This transformation will be based only on DL inference characteristics, e.g., the dependency between the neurons of a given layer and the next layers.
- S2: The second stage, denoted as S2, will transform the resulting DAGs of S1 into a set of task specifications.
- S3: This stage consists in achieving schedulability tests and sub-task-to-core allocation. The goal of this stage is to choose a single concrete task for every task specification.
- S4: In this stage, concrete DAGs will receive the last transformation by generating C-code for the CPU, GPU, and the other accelerators. This transformation is described in WP4.
Start date: 01/10/2023, End Date: 30/09/2027