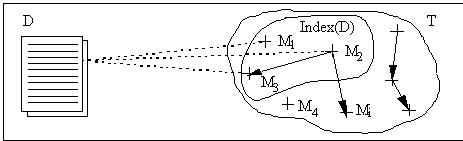
fig.1 - indexation d'un document D à l'aide d'un thésaurus T.
Les flèches représentent des liens entre les éléments Mi du thésaurus
Acquisition de terminologie à partir de gros corpus
Chantal ENGUEHARD
Institut de Recherche en Informatique de Nantes
IUT, 3, rue du Maréchal Joffre
44041 Nantes Cedex 01 - France
tel : 40 30 60 52
fax : 40 30 60 53
email : enguehard@iut-nantes.univ-nantes.fr
Résumé
L'acquisition automatique de la terminologie d'un domaine est un axe
de recherche important en traitement de la langue naturelle, particulièrement
dans le cadre de l'indexation automatique de textes et pour la génération
de textes où la connaissance de structures idiomatiques est essentielle.
Le système ANA (Apprentissage Naturel Automatique) constitue
une nouvelle approche pour l'acquisition automatique de terminologie. Ce
système est directement inspiré par l'apprentissage humain
de la langue maternelle. D'une part, nous avons tenté de modéliser
la capacité humaine à reconnaître des informations
dont la morphologie varie alors que leur sémantique reste sensiblement
la même. D'autre part, nous avons également représenté
les processus d'induction et de généralisation.
Quand il n'y a pas de thésaurus du domaine considéré,
les descripteurs sont choisis librement, mais la qualité de l'indexation
baisse fortement comme l'a montré BETTS [BETTS 91]. Or de nombreux
domaines ne disposent pas de thésaurus préétabli,
surtout les domaines concernant des sciences ou des techniques récentes.
La constitution manuelle d'un thésaurus fait appel aux compétences
d'ingénieurs documentalistes et de spécialistes du domaine.
Il s'agit d'un processus lent et coûteux qui n'est généralement
pas réalisé lors de la mise en place d'un système
documentaire.
Ce problème a été abordé suivant différentes
approches, généralement par le biais de l'indexation. Il
s'agit alors de sélectionner des descripteurs dans le but d'indexer
des textes. Nous distinguons les approches manuelles et automatiques. Ces
dernières regroupent les systèmes statistiques, linguistiques
et mixtes (regroupant des procédures statistiques et linguistiques).
Les approches manuelles sont les plus souvent utilisées bien
qu'elles soient de très mauvaise qualité : les index sont
incomplets et inconsistants (ils dépendent très fortement
de la personne qui les détermine).
Les approches statistiques sélectionnent les termes en fonction
de leur pouvoir discriminatoire entre les documents ou en se référant
à une loi statistique. Ils sont peu fiables pour cause de bruit
(voir [CHUR 89] par exemple).
Les approches linguistiques reposent principalement sur des patrons
syntaxiques. Ces procédures sont plus ambitieuses, donnent d'excellents
résultats, mais elles présentent l'inconvénient de
fonctionner à l'aide de volumes de connaissances importants, dictionnaire
et grammaire, qui doivent être préalablement décrits
[EVAN 91].
Les systèmes mixtes utilisent à la fois des procédures
linguistiques et statistiques et donnent de bons résultats. Dans
cette catégorie nous trouvons quelques systèmes commercialisés.
Citons TERMINO [DAVI 90] qui se base uniquement sur des patterns syntaxiques,
et n'utilise donc pas de lexique, et SPIRIT [ANDR 83] qui apprend la syntaxe
à partir des textes et n'utilise donc pas de grammaire prédéfinie.
Je ne détaille pas plus cet état de l'art déjà
réalisé de façon plus complète dans le chapitre
I de [ENGU 92] (p.13-49).

figure 2 : extrait de corpus
Cette situation particulière interdit l'utilisation des méthodes mixtes précédemment citées : SPIRIT a besoin d'un dictionnaire dont nous ne disposons pas ; TERMINO utilise une grammaire, or nos textes ne sont pas écrits selon une syntaxe correcte et il apparaît impossible de les analyser suivant une grammaire prédéterminée.
Aucun système ne répondant à notre problème,
nous avons donc choisi de développer un nouveau système d'acquisition
automatique de terminologie.
Rappelons que la fonctionnalité principale de ce processus est
la détermination automatique d'éléments de terminologie
appelés termes.
Un terme est un élément du lexique
- spécifique du domaine
exemple : "CABLE", "CHAMBRE D'IONISATION".
- circonstanciel, indépendant du contexte
exemple : "ANNEE 1988" est un terme,
"ANNEE DERNIERE" n'en est pas un.
Pour plus de clarté, un terme est toujours écrit en lettres
capitales.
Nous exprimons cette induction par le postulat :
La cooccurrence fréquente d'événements
est significative.
A cette capacité de généralisation, il faut ajouter
le don humain à manipuler des données vagues, par opposition
à l'ordinateur qui est sans égal pour les calculs mais se
montre trop rigide dans les domaines plus flous [STEI 73].
En langue naturelle, dans le cadre de la détermination de terminologie,
la même notion peut être représentée sous différentes
formes. Par exemple, dans "la pompe fuit", "fuite de la cuve et de la pompe"
et "il y a une fuite à la pompe", il est toujours question d'une
pompe qui fuit.
Des recherches se sont orientées vers la reconnaissance d'éléments
de terminologie sous leurs différentes formes en utilisant les variations
morphologiques (la marque du pluriel par exemple) et syntaxiques préalablement
identifiées [COUR 90]. D'autres approches évitent la formalisation
manuelle de ces variations par l'extraction automatique de transformations
des éléments de terminologie à partir d'un ensemble
de termes et de corpus bruts. Les règles ainsi établies sont
ensuite généralisées et utilisées pour la reconnaissance
de termes sous leur diverses morphologies ("la pompe qui fuit" et "fuite
de la pompe" par exemple) [ROYA 93].
Pour résoudre ce problème nous avons doté le système
ANA de quelques opérateurs souples qui lui permettent de reconnaître
des termes sous plusieurs variations morphologiques. Ces opérateurs
ne sont pas parfaits : les taux de rappel et de précision( ) ne
sont pas égaux à 1. Cependant, les performances sont satisfaisantes
dans le cadre de notre application. Ils présentent l'avantage d'être
simples et non spécifiques à une langue particulière.
(Ces opérateurs sont définis en annexe).
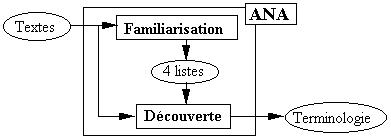
Le module de familiarisation extrait automatiquement quelques éléments
de connaissance (sur la langue utilisée et le domaine abordé)
sous la forme de quatre listes. Le module de découverte utilise
ces quatre listes ainsi que le corpus de textes à étudier
pour sélectionner la terminologie du domaine abordé.
- Les mots fortement liés sont des chaînes de caractères
comprenant des caractères blancs mais pourtant considérés
comme des mots.
Ces mots sont le résultat de la variation morphologique
de certains mots fonctionnels.
Ainsi, "de" devient "des" au pluriel, "de la" au féminin
et "du" au singulier.
Cette liste comprend généralement moins de 10 éléments
qui sont ajoutés à la liste des mots fonctionnels.
exemple {"de l", "de la", "est en", "et la" "est le", "la on", "on
a"}
- Les mots de schémas sont des mots fonctionnels structurant
des syntagmes.
Il y a généralement moins de 10 éléments
dans cette liste.
exemple {"de", "de la", "des", "du" "en"}
- Le bootstrap est un ensemble de quelques termes du domaine
dont il est question dans le corpus de textes. Une vingtaine d'éléments
suffisent. Cependant le bootstrap peut être constitué de beaucoup
plus d'éléments.
exemple {"AUTOMATE", "CENTRALE", "CHAUDIERE", "CIRCUIT", "COEUR", "COLLECTEUR",
"CONCEPTION", "CREYS", "CUVE", "DALLE", "DEVERSOIR", "ECHANGEURS", "FREQUENCE",
"GAZ", "HELIUM", "INSTRUMENTATION", "INTERCUVE", "PHASES", "PHENIX", "POMPES",
"PRESSION", "PUISSANCE", "REACTEUR", "REFROIDISSEMENT", "REMPLISSAGE",
"RETENTION", "SIPHON", "SODIUM", "SOUDURES", "STRUCTURES", "SURETE", "TEMPERATURE",
"TUBES", "VIBRATIONS", "VIDANGE", "VIROLE", "VITESSE"}
Les procédures mises en oeuvre dans la phase de familiarisation
sont détaillées dans [ENGU 92] (pages 110 à 128).
Le postulat (La cooccurrence fréquente d'événements
est significative.) est interprété dans le cadre du traitement
de la langue naturelle :
- Un événement est une occurrence d'un mot fonctionnel,
ou d'un terme, ou d'un mot de schéma, ou d'un mot quelconque non
répertorié dans ces trois listes.
- Deux événements sont cooccurrents s'ils sont séparés
par W mots (non fonctionnels) ou moins.
(Cette notion de cooccurrence rejoint les 'collocations' définies
comme des couples de mots fréquemment voisins [CHOU 88].)
ANA distingue trois types de cooccurrences d'événements qui s'excluent mutuellement :
- type expression : cooccurrence de deux termes
exemple ... "le" "COEUR" "du" "REACTEUR"
"est" "constitue" ...
- type candidat : cooccurrence d'un terme et d'un mot séparés
par un mot de schéma.
exemple ... "la" "CUVE" "du" "barillet"
"est" "remplie" ...
- type expansion : cooccurrence d'un terme et d'un mot.
exemple ..."ici" "ensuite" "les" "STRUCTURES"
"internes" "se" ...
L'algorithme de découverte de nouveaux termes dans un texte fait apparaître quatre étapes. Il s'agit d'un processus incrémental.
Pour les occurrences comprenant deux termes (type expression), la chaîne
de caractères qualifiée en tant que nouveau terme inclut
ces deux termes.
exemple 1 : occurrences de "COEUR" et de "REACTEUR" :
"COEUR" "du" "REACTEUR"
"COEUR" "du" "REACTEUR"
"REACTEUR" "dont" "le" "COEUR"
"COEUR" "du" "REACTEUR"
"COEUR" "de" "ce" "REACTEUR"
"COEUR" "le" "REACTEUR"
La chaîne de caractères "COEUR DU REACTEUR" apparaît
fréquemment et devient un nouveau terme.
Pour les occurrences de type candidat comprenant un terme, un mot de
schéma et un mot, c'est ce mot qui sera qualifié en tant
que nouveau terme.
exemple 2 : occurrences de "CUVE" et d'un mot de schéma :
"CUVE" "du" "barillet"
"CUVE" "du" "barillet"
"CUVE" "du" "barillet"
Le mot "barillet" apparaît fréquemment dans la même
configuration. Il devient un nouveau terme.
Enfin, dans les occurrences ne comprenant qu'un terme et aucun mot de
schéma (type expansion), le nouveau terme sera une chaîne
de caractères qui inclut le terme et un autre mot (non fonctionnel).
exemple 3 : occurrences de "STRUCTURES" sans autre terme ni mot de
schéma
"ici" "ensuite" "les" "STRUCTURES" "internes"
"sans" "les" "STRUCTURES" "acier"
"conception" "des" "STRUCTURES" "internes"
"assembler" "les" "STRUCTURES" "externes"
"demonter" "les" "STRUCTURES" "internes"
"compter" "avec" "les" "STRUCTURES" "externes"
La chaîne de caractères "STRUCTURES INTERNES" apparaît
fréquemment et devient un nouveau terme.
Ces nouveaux termes sont ajoutés au bootstrap et seront pris
en compte pour le prochain traitement du texte en cours ou pour le traitement
du texte suivant.
Le processus de traitement d'un texte s'arrête lorsqu'aucun nouveau
terme n'apparaît pendant un cycle.
| BALLON POMPE | ANALYSE DES SIGNAUX |
| BOUCHON LRG | CALCUL A L AIDE DU CODE |
| CHAINE D ACQUISITION | CHAMBRE A FISSION HAUTE TEMPERATURE |
| CORROSION INTERGRANULAIRE | DESSUS DE LA DALLE |
| DIFFERENTS COMPOSANTS | DISCRIMINATION |
| ENREGISTREMENT DE LA PUISSANCE MOYENNE DU BRUIT | ESSAIS DE FATIGUE |
| EXAMENS ET CONTROLES EFFECTUES SUR LES PIECES DU MECANISME | EXPANSION THERMIQUE |
| ETAT DE SURFACE | ETUDES DES RUPTURES SECONDAIRES CONSECUTIVES |
| EVOLUTION THERMIQUE ET HYDRODYNAMIQUE D UN GENERATEUR DE VAPEUR DU TYPE | FOIS QUE C EST FAIT |
| GENERATEURS DE VAPEUR A TUBES DROITS VERTICAUX | INDICATEUR DE NIVEAU DISCONTINU SONDE |
| INTERACTION SODIUM PARAFFINE | MISE AU POINT EN AIR |
| ORIGINE | PIVOTERIE |
| POMPE SECONDAIRE DE LA BOUCLE | POSSIBILITES DE DETECTION |
| PROBLEMES D AEROSOLS | PROTOTYPE DE SPX1 |
| RAPPORT DE SURETE | REACTEUR DU FUTUR |
| RICHARDSON | SOUMIS A UNE DECOMPRESSION RAPIDE |
| THERMIQUE IMPORTANTE | VERIFIER EN REACTEUR |
Les spécialistes du domaine ont été satisfaits
par environ 75 % des termes.
| ANALYSE | ANALYSE POLLINIQUE |
| ANALYSE TRANSACTIONNELLE | APICULTEURS DE PROVENCE |
| APPELLATIONS | ASSOCIATION |
| BASSE QUALITE | BRUYERE |
| CENTRALES D ACHAT | CONCERNE LE MIEL |
| CREATION | CRU |
| CREATION DE MARQUES | ESPRIT DU CONSOMMATEUR |
| GARANTIE | GOUT |
| GOUT DU MIEL | GRANDES SURFACES |
| GESTION DU LINEAIRE | INDICE |
| ORIGINE FLORALE | MARCHE |
| MIEL DE TOURNESOL | MONTAGNE |
| PETITS APICULTEURS | PRIX MOYEN |
| POTS DE 250 | QUANTITE |
| TRADITION DE PRODUCTION | VENTE DIRECTE PAR LE PRODUCTEUR |
| STRATEGIE PUSH | TONNES |
L'évaluation par expert a conclu à un taux de 80 % de
termes corrects.
La phase de découverte a utilisé les listes suivantes
:
34 mots fonctionnels : {"a", "an", "and", "any", "are", "as", "at",
"be", "between", "by", "can", "down", "each", etc.}
2 mots de schémas {"of", "of the"}
29 éléments de bootstrap.
| ACOUSTIC BOILING NOISE DETECTION | ACOUSTIC LEAK DETECTION |
| ACOUSTIC LEAK DETECTION SYSTEM | ACOUSTIC SOURCE LOCATION |
| ACOUSTIC SURVEILLANCE | ACOUSTIC SURVEILLANCE TECHNIQUES FOR SGU LEAK |
| ANALYSIS OF ACOUSTIC | ANALYSIS OF ACOUSTIC DATA FROM THE PFR SGU CONDITION MONITOR |
| ANALYSIS OF ACOUSTIC DATA FROM UK SODIUM WATER REACTION | ARRAY PROCESSING |
| ATTENUATION | ATTENUATION IN X CELL |
| ATTENUATION OF ACOUSTIC SIGNAL | BACKGROUND NOISE IN A SGU |
| BEEN SET | BEFORE THE PULSE |
| BEST ESTIMATED SOURCE LOCATION | DIAMETER OF THE SUBASSEMBLY |
| DISTANCE TRAVELED IN CELL | DROP VELOCITY |
| ESTIMATE | ESTIMATED SOURCE LOCATION |
| LOCATION ANALYSIS | MEASUREMENT |
| REACTOR BACKGROUND NOISE | REACTOR CORE |
| SIGNAL AMPLITUDES | SIGNAL ATTENUTION |
| SIGNAL PROCESSING | SIGNAL PROCESSING TECHNIQUES |
| SIGNAL STRENGTH | SIGNAL TO NOISE RATIO |
| TEMPERATURE COEFFICIENT OF VELOCITY | ULTRASONIC PULSES |
| ULTRASONIC TRANSDUCER | USING ULTRASONICS |
| VELOCITY OF SOUND | VELOCITY OF SOUND IN SODIUM |
Ces résultats n'ont pas pu être évalués selon
la procédure utilisée habituellement.
Nous envisageons d'améliorer les résultats d'ANA.
En effet, le taux de satisfaction des spécialistes pourrait
être nettement amélioré en effectuant une correction
rapide des résultats. Ainsi, dans le deuxième groupe de résultats
présentés, nous trouvons "FOIS QUE C EST FAIT" qui pourrait
être supprimé. "ETUDES DES RUPTURES SECONDAIRES CONSECUTIVES"
et "INDICATEUR DE NIVEAU DISCONTINU SONDE" pourraient être tronqués
en "ETUDES DES RUPTURES SECONDAIRES" et "INDICATEUR DE NIVEAU DISCONTINU"
qui sont parfaitement corrects.
On peut envisager une correction partiellement automatisée dans
le cas de terminologies de volume important (comme c'est le cas pour Super-Phénix).
Une grammaire automatiquement extraite à partir d'un sous-ensemble
de termes corrects pourrait effectuer le tri entre les éléments
acceptables ou non.